-

新手快速上手如何启用高防CDN?常见问题与解决方案集合
2026/5/25 -

选择建议比较报告高防和cdn哪个好在不同场景下的结论
2026/5/26 -

实用命令和在线平台教你 怎么判断网站有没cdn 更准确
2026/7/13 -

面向中小企业的网站 cdn 成本优化与效果评估报告
2026/7/11 -

地方监管对cdn行业牌照要求的更新与企业应对策略
2026/6/18 -

如何通过测试来验证cdn和高防哪个好能满足峰值流量
2026/5/16
工具书式高防cdn搭建教学列出最佳实践与常见反模式警示
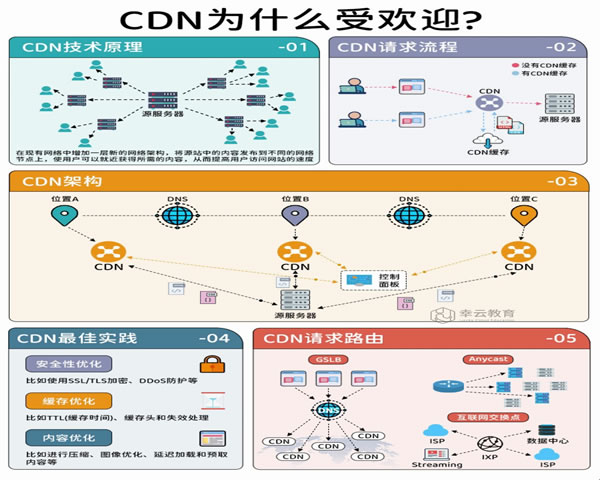
本文以工程化视角概括了构建企业级抗攻击与加速能力的关键要点:从防护层级、节点与厂商选择,到策略配置、监控验收与常见反模式的避免,提供可操作的清单与注意事项,便于安全和运维团队快速落地并长期维护。
要包含多少防护层级才能达到稳定抗DDoS效果?
一个稳健的架构应当至少包含边缘过滤、清洗节点、应用防护与源站加固四个层级。边缘由高防CDN完成初始吸收与缓存,清洗节点负责大流量分流与协议异常处理,应用层通过WAF与速率限制防止复杂攻击,源站配合最小化暴露面和带宽预留作为最后防线。每层都需有明确的SLA与流量链路可追溯性。
哪个节点或厂商更适合我的业务场景?
选择时关注三个维度:全球/本地覆盖与延迟、清洗能力(并发连接、报文解析、行为识别)、以及运维与联动能力(应急SOP、流量切换)。对于对延迟敏感的业务优先选择边缘覆盖广的CDN;对常受大流量攻击的业务应评估厂商的清洗带宽与历史攻防案例。优先选能提供API化控制与联合演练支持的合作方。
如何配置WAF、速率限制与缓存策略以减少误判与漏判?
先从白名单+黑名单基础规则起步,逐步引入行为学检测与自适应阈值。针对API或非缓存内容,采取细粒度的速率限制并结合验证码机制;静态资源通过合理TTL与分片缓存降低源站压力。把攻击轨迹打上日志并用低误报阈值回放,定期调整签名规则避免业务规则冲突。
在哪里部署边缘与清洗节点能实现最佳性价比?
清洗节点应靠近攻击集中点与主要骨干出口,边缘节点布局以用户分布为准。国内外混合部署时,优先在高风险区域(流量入口、承载核心业务的省会或IX)布置更强的清洗资源。对小型业务,可采用云厂商按需弹性清洗以节约成本;大型互联网业务则需自建或与多家供应商做N+1冗余。
为什么一些常见反模式会导致防护失效?
常见反模式包括:仅依赖单一厂商或单一清洗点、把所有流量全部回源以节省成本、忽视日志与回放、以及将防护配置直接硬编码在源站。单点故障、盲目省钱和缺乏可验证性都会在攻击来临时放大损失。引入多层冗余、流量分流策略与持续演练可有效规避这些风险。
怎么持续验证与优化高防CDN的实际效果?
建立定期演练(包括桌面演练与压力测试)和实时监控体系:流量异常告警、清洗效率指标、误报率统计与业务可用性。利用蓝绿/金丝雀发布验证新策略,记录每次变更的回滚点。应用A/B测试来衡量不同速率限制或WAF规则对真实用户体验的影响,形成可度量的优化闭环。
哪个指标最能反映防护策略是否生效?
关键指标有清洗吞吐率(Gbps)、异常连接数拦截率、业务SLA(响应时延与可用性)、误报率与回滚频率。不要只看单一带宽数字,结合业务层指标(如交易成功率、页面加载时间)能更直观地判断策略是否破坏了正常流量。
怎么避免部署过程中的常见误区与运维陷阱?
避免把所有配置一次性上线;采用灰度发布、日志回放和回退计划。制定清晰的SOP,明确联动链路(CDN厂商、ISP、源站运维、安全应急团队)。定期演练DNS切换与BGP策略,保证在链路受损时能快速切换,减少业务中断时间。
构建