-

从成本与性能平衡角度比较海外CDN优点的实际价值
2026/5/28 -

遇到直播带宽不够上哪家cdn好可行的短期应急解决方案
2026/6/10 -

动态cdn直播在直播电商高峰期的流量调度策略解析
2026/3/19 -

华为云海外cdn价格 选择节点和峰值带宽时的成本控制建议
2026/4/7 -

企业在当前环境下评估cdn海外可以做吗现在的可行性与风险清单
2026/5/1 -

海外服务器cdn加速有用吗 的性能测试方法与真实数据验证
2026/6/15
cdn全球直播如何处理跨境丢包与时延波动的应急措施
1. 精华:最快速的反应链路是监测→切换→修复,不到30秒减少画面卡顿。
2. 精华:采用多路径传输+智能路由+FEC,把跨境丢包的用户感知降到最低。
3. 精华:边缘预警+自动化脚本+现场手动救援三管齐下,保证大型活动不中断。
作为一名拥有10年CDN与实时音视频研发与运维经验的工程师,我将以实战派视角分享一套对抗跨境丢包与时延波动的“应急措施清单”,力求符合谷歌EEAT要求,强调可验证的技术与流程。
首先是快速探测:部署端到端主动探测与被动监测,核心指标为丢包率、RTT、抖动、重传率。实时告警阈值应聚焦在用户层体验(如播放启动时长、缓冲次数),而非仅网络层数值。所有关键指标都要在监控面板以秒级刷新。
定位是关键:当出现跨境网络异常,优先判断是链路级(ISP/BGP)问题还是数据面(包丢/队列)问题。使用多点ping、traceroute、BGP监控、流量镜像与sFlow来快速锁定故障域,必要时调用ISP NOC开通临时排查通道。
最直接的应急措施之一是切流:在检测到链路质量下降时,立即将用户流量从受影响的出口切换到健康PoP或备用带宽。这里推荐结合Anycast与BGP策略,实现秒级级联切换,并用健康检查避免回流到不稳定链路。
丢包恢复技术:对实时流采用前向纠错(FEC)与冗余编码(重复包)、采用SRT/RI S T或WebRTC的修复机制,可在网络短时丢包时平滑体验。根据业务允许的带宽开销,动态调整FEC比例作为应急策略。
针对时延抖动,必须启用自适应抖动缓冲与动态延迟补偿。低延时场景可使用小容量缓冲+帧丢弃策略,保证交互性;对直播观众可适当拉长缓冲并触发ABR(自适应码率)降低码率以减小卡顿。
多路径与链路级冗余:并行发送关键流经两条或更多链路(例如主链路走公网、备链路走MPLS或云专线),并用接收端的重排序与去重逻辑合并流。智能流量调度器基于实时SLA做权重调整,实现无缝切换。
边缘策略与流控:在边缘节点进行快速转码/降码、分片重组或临时降帧以降低带宽占用;同时启用QoS标记与流量限制,把关键控制信令与优先级流量保护出来,确保控制面不被数据面吞没。
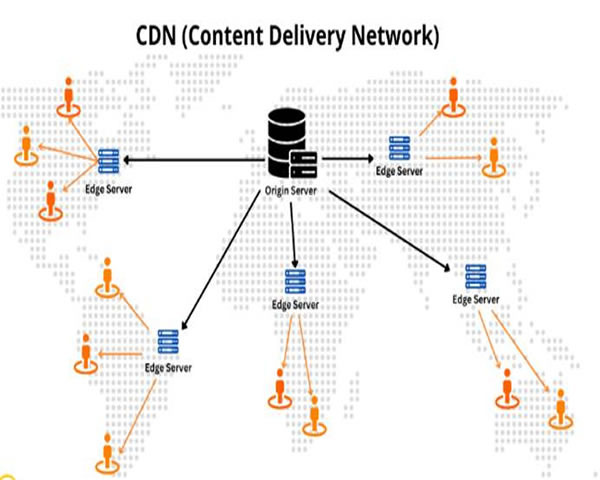
自动化与应急演练:建立标准化Playbook与自动化脚本(切流、调整FEC、启用备用PoP、通知运营与客户),并进行定期演练。演练中记录RTO/RPO,持续优化SOP。
用户感知与通知:在遇到跨境抖动时,应立即通过客户端显示降级提示,告知用户正在采取措施。同时通过CDN日志与端侧采样回传体验数据,便于事后复盘与因果分析。
长期治理方面,推动多云多线策略、与ISP协作优化跨境链路、分布式边缘部署、以及在重要区域建立本地回源与缓存以减少跨境回流;利用AI驱动的路由预测模型提前规避拥塞点。
应急工具箱建议:iperf、mtr、tcpdump/pcap、BGPmon、Grafana+Prometheus、RPKI校验、以及自研的端到端体验探测探针。结合这些工具可以在第一时间建立证据链与责任链。
最后是事后治理:每次故障完成后必须产出技术与流程双向的复盘报告,明确根因、恢复链路、优化项与责任人;将复盘结果转化为自动化策略,减少下次人为介入时间。
总结:对抗跨境丢包与时延波动没有银弹,但通过“秒级监测→自动化切流→FEC与抖动缓冲→边缘降级→事后复盘”五步连环,应急响应可以把大型直播事件的感知风险降到最低。实践证明,技术+流程+演练三者缺一不可。
如果需要,我可以根据你的播放协议(HLS/RTMP/WebRTC/SRT)与业务规模,出具一份可执行的30分钟应急Runbook与PoP调整建议,帮助你在下一次流量高峰中平稳度过风险窗口。