-

如何判断不限内容高防cdn是否适合自有平台需求
2026/7/2 -

cDN_B与传统CDN在多区域同步与一致性处理上的区别解析
2026/6/14 -

cdn防ddosDDoS高防评价对中小企业采购的参考价值
2026/5/13 -

决策流程模板该选高防ip还是cdn高防从需求到上线的一步步分析
2026/5/28 -

如何评价cdn浴霸在加速和稳流方面的实际效果
2026/5/24 -

IT860 高防 CDN 网站成功案例分享提高访问稳定性的方案
2026/3/20
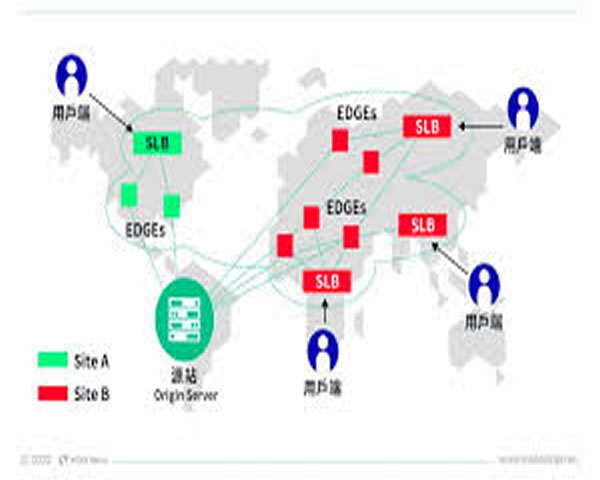
如何监控cdn星河服务并快速定位异常与回落策略
本文概览了面向CDN星河服务的监控体系和应急流程,涵盖需要关注的关键指标、快速定位异常的方法、告警与回落节点的部署位置,以及为什么和如何设计自动与手动回落,以便在链路或节点故障时迅速恢复用户体验。
多少指标需要持续监控?
监控粒度应覆盖业务面与基础设施面两类指标:业务体验类(如命中率、首字节时延、成功率、带宽及并发)和基础设施类(如节点健康、上游源响应、DNS解析、带宽饱和度)。建议至少持续关注5~8个关键指标,将它们纳入性能监控仪表盘实现多维度联动分析。
哪个指标最先反映用户感知异常?
通常是首字节时延(TTFB)、请求成功率和缓存命中率最能反映用户体验。当TTFB上升同时成功率下降,且命中率无明显变化,说明可能是上游或网络链路问题;如果命中率骤降,优先怀疑缓存失效或配置变更引起的回源激增。
如何快速定位异常根因?
构建流程化的排查路径:首先查看全局告警与拓扑图,锁定受影响区域;其次聚合时间序列数据对比正常窗口,定位指标突变点;再通过分支排查(节点、POPs、上游源、DNS),利用日志链路和抓包确认请求路径。利用标签化的监控数据能加快快速定位。
哪里应当设置告警与回落触发点?
告警应分层设置:临界预警(轻度波动)在运维中台触发,严重告警在SRE/值班工程师和自动化系统触发。回落触发点建议设在边缘节点与流量调度层:当某POP的错误率或延时超阈且持续超过N分钟,应自动从该POP回落到备用线路或直接回源。
为什么必须设计回落策略而非只靠告警?
告警只是通知,而回落是保障业务连续性的手段。没有自动回落,故障会迅速扩大影响范围并造成用户体验下降。合理的回落策略能在故障窗口内维持服务可用性、避免雪崩效应,并为后续人工排查赢得时间。
怎么实现自动与手动回落的配合?
实践中采用“先自动、后人工”的模型:设置多级阈值与冷却周期,低级阈值触发自动流量切换或限流策略,高级阈值或复杂场景触发人工介入。自动化实现依赖于流量调度器、负载均衡和脚本化运维接口,同时保留人工回滚入口和回放日志以便审计。
怎样优化与演练以确保策略有效?
定期进行混沌演练与故障切换演练,验证告警连通性、回落链路和恢复时间目标(RTO)。同时维护故障知识库,基于历史事件不断调优阈值与回落流程,确保在真实事故中系统能按预期进行监控与回落。